Airflow : un chef d’orchestre pour nos transformations de données
- Publié:

Airflow a été initialement développé par Airbnb et rendu Open Source en 2014 avant d'être repris par la fondation Apache pour continuer son développement.
Il totalise à 18.6k ⭐ sur son dépôt Github.
Il permet de surveiller l’exécution de processus de traitement (ou workflows) en interface graphique et est codé et configurable entièrement en Python. C’est un orchestrateur de processus. Une fois le processus configuré en Python, Airflow gère son exécution et sont lancement. Cette technologie a pour philosophie : "configuration as code".
1. Pourquoi Airflow ?
Dans un contexte de Big data il faut pour l’entreprise un moyen de gérer ses processus de collecte et traitement de données afin de s’assurer que tout tourne correctement. Les données générées par nos entreprises sont diverses: que ce soit des données structurées, des excels, du contenu multimédia, des bases de données RH ou client etc… Grace aux services Cloud, comme Amazon Web Services (AWS) ou Microsoft Azure, on peut aujourd’hui stocker tout ce qu’on veut grâce à un vaste panel de services managés tels que Amazon S3, Redshift etc.. Ces formats différents ainsi que des cas d’usage métier variés qui obligent les données à se déplacer et changer de forme pour être utilisées par tous les services (dans des tableaux de bord, de la prediction ou des logiciels internes).
Mais comment faire pour que tous nos processus de transformation de données tournent comme une horloge tout en ayant accés à une interface de gestion ? ... Welcome to Airflow !
Airflow est devenu de facto l’outil privilégié pour effectuer ces taches de par sa communauté mais aussi sa robustesse et sa flexibilité.
Il est là pour aider les Data Engineer à créer et configurer les processus de collecte/transformation/stockage de données (plus couramment appelé ETL pour « Extraction Transformation Load » ou Workflows). Airflow ressemble au système de crons, qui permet d'exécuter des scripts sur Unix, en y ajoutant des outils, une interface, une gestion des erreurs...
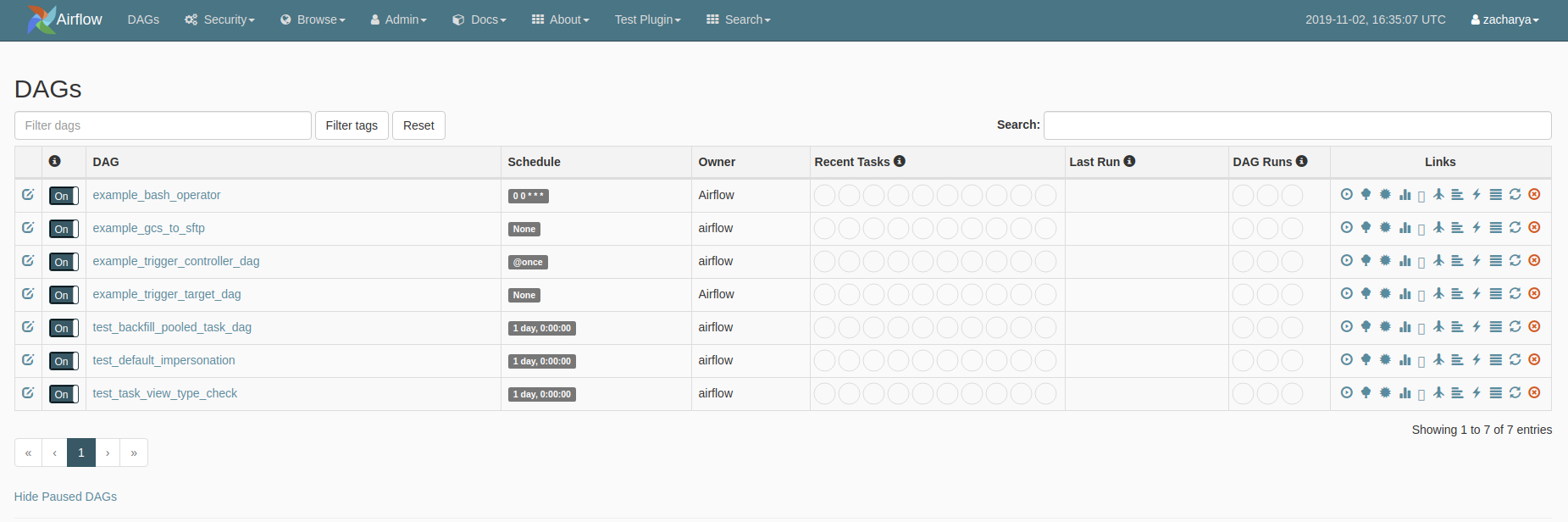
2. Comment ça marche ?
Airflow s'installe facilement en éxécutant la commande d'installation de librairie Python : $pip install apache-airflow. On initialise la base de données avec $airflow initdb
L'architecture d'Airflow repose sur plusieurs composants :
- Un orchestrateur de tâches (ou Task Scheduler) : c'est le coeur du réacteur, c'est lui qui priorise, lance, relance ou abandonne les tâches.
- Un ou plusieurs éxécuteur(s) de tâches (ou Task Executor): il assure l'éxécution de chaque tâche demandée par l'orchestrateur.
- Une interface web pour avoir une vision d'ensemble des processus en cours ou passés.
- Une base de données pour stocker les états d'éxécution et les logs.
Chaque processus est configuré sous forme de DAG (pour Directed Acyclic Graph) qui regroupe un sous ensemble de tâches à effectuer dans un certain ordre. Ceci revient à créer un graph de tâches reliées entre elles. Ces processus DAG sont prévus à des heures précises et leur exécution peut être surveillée en interface graphique au travers des fichiers de logs générés.
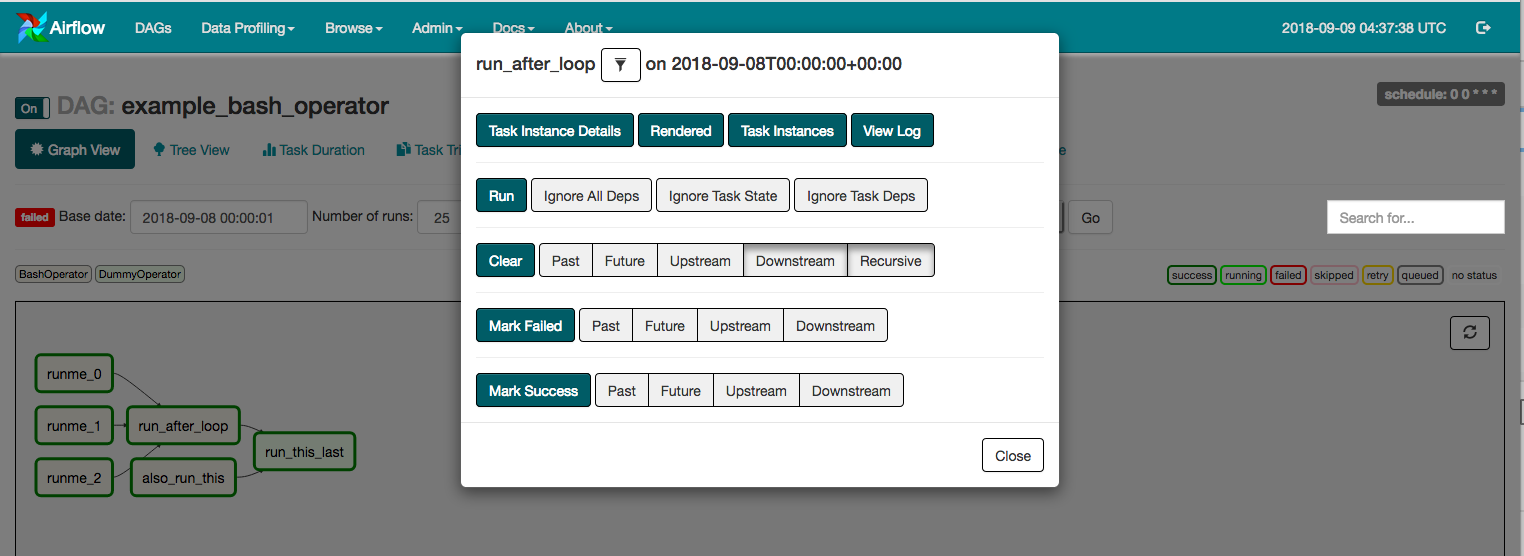
Tous ces DAGS sont codés et configurés en Python. Le fait que les pipelines soient codés en Python apporte une grande souplesse et un large choix d’exécutions possibles.
L'orchestrateur va surveiller les DAGs et va déclencher les tâches lorsqu'il le faudra dans le bon ordre. Il va faire ceci en vérifiant périodiquement l'état des tâches en base de données (succés/échec de la tâche) et voir les connexions entre ces tâches selon le DAG. la configuration se fait dans le fichier airflow.cfg et l'orchestrateur est lancé avec la commande $airflow scheduler dans le terminal.
Les éxécuteurs sont responsables de lancer les tâches demandées par l'orchestrateur. Ils gérent l'allocation des ressources. Par défaut Airflow utilise le SequentialExecutor mais celui ci est trés limité et c'est le seul qui fonctionne avec SQLite (la base de données par défaut). Il en existe d'autres comme DebugExecutor, LocalExecutor, DaskExecutor, CeleryExecutor ou KubernetesExecutor. Le CeleryExecutor est certainement une meilleure option que le SequentialExecutor car il peut exécuter plusieurs workers pour exécuter une action et en distribuant les ressources.
Le serveur web permet d'avoir accés à une interface utilisateur pour surveiller l'exécution des DAGs et tâches et pour déboguer. On peut également lancer des tâches arbitrairement et avoir des statistiques sur les temps d'exécution.
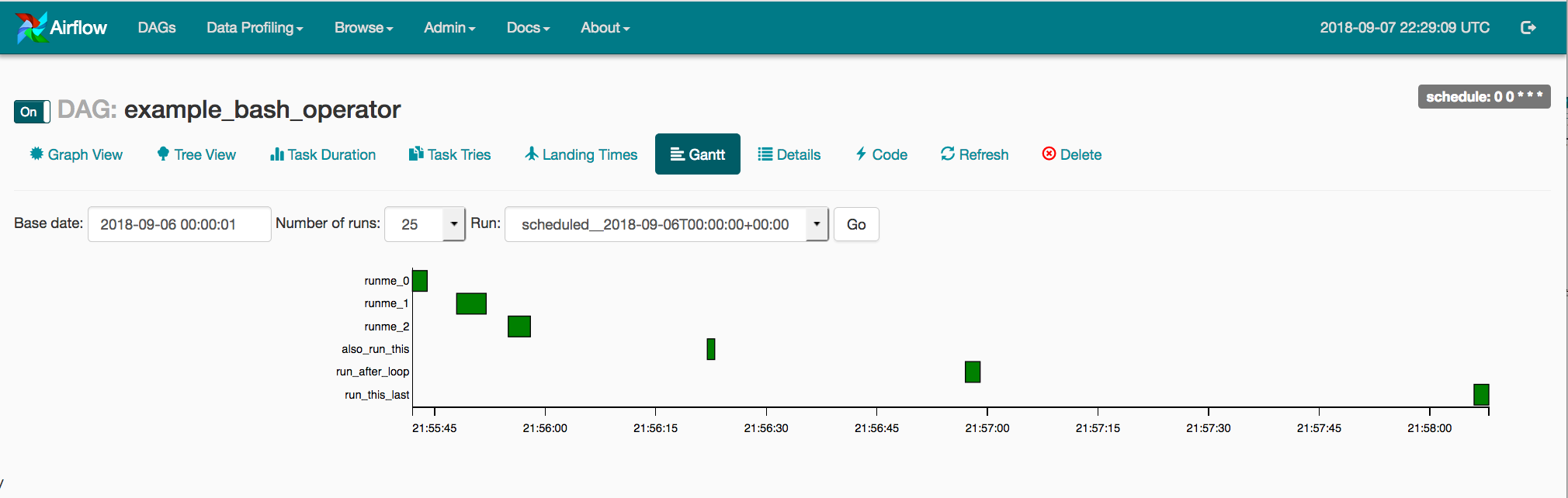
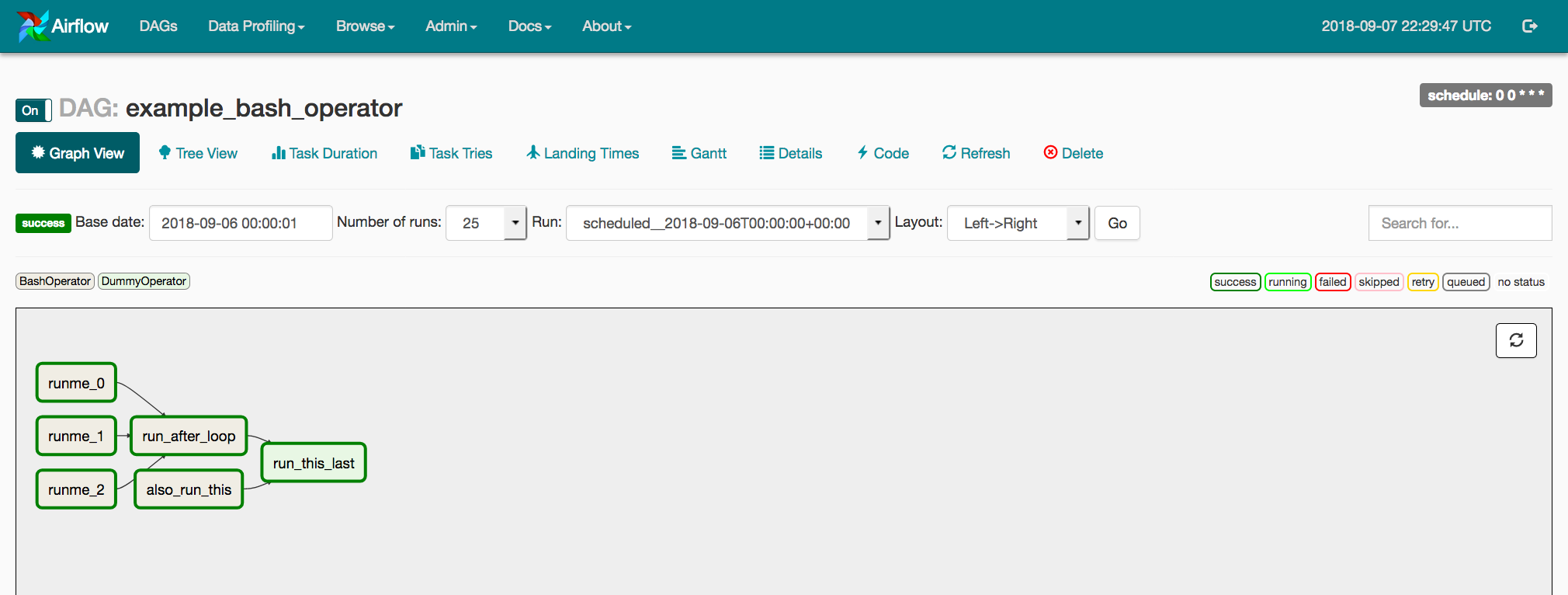
3. Configuration d'un processus (ou DAG)
Grâce au concept de DAG, Airflow nous permet d'organiser et d'optimiser l'exécution de nos sous tâches.
Chaque tâche contient le code qui va être exécuté au traver d'opérateurs. Ces opérateurs permettent de faire quasi tout ce qu'on souhaite, que ce soit du code Python, des commandes Bash ou encore l'utilisation de Spark. Le travail de collecte, transformation et stockage est effectué au travers de ces opérateurs. Ce peut être une requête API, de l'agrégation de données de sources différentes, le téléchargement de fichiers distants pour les stocker sur notre infrastructure, des statistiques, de l'A/B testing, des routines quotidiennes (ou Batch) à faire sur les serveurs... Il existe des opérateurs pour s'interfacer avec tout type de base de données et de services managés chez les hébergeurs (ex: AwsBatchOperator).
La liste est disponible ici ! Il est également possible de créer nos propres opérateurs (qui peuvent hériter d'existants) et les sauvegarder dans notre dossier './plugin'.
Il est possible de faire transiter des données ou des éléments de contexte entre deux tâches grâce aux fonctions x-com. Ceci rend plus facile la création de processus de traitement.
Il existe également des capteurs (ou Sensors) qui permettent de déclencher des actions selon un événement. Il peut être vu comme un opérateur particulier qui exécute une tâche longue d'écoute. Par exemple il y a le capteur GoogleCloudStorageObjectSensor qui attend l'existence d'un fichier dans le service de stockage "Google Cloud Storage" pour enclencher une suite de tâches.
La liste des capteurs ici.
Je vais vous montrer comment configurer un premier DAG maintenant. Il est composé de 2 tâches qui exécutent des commandes Shell Bash. On utilisera alors l'opérator BashOperator.
On commence par importer airflow, l'opérateur et les packages nécessaires à notre traitement. Ensuite nous définissons notre DAG avec les arguments comme par exemple quand il va être lancé, son nom, les configurations de notification par mail si besoin et les tentatives.
Viennent ensuite les tâches (t1 et t2) qui prennent un ID, les commandes à passer à l'opérateur et le DAG auquel elles sont rattachées. Ici t1 affiche la date et t2 attend 5sec.
from datetime import timedelta
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.utils.dates import days_ago
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
dag = DAG(
'test',
default_args=default_args,
description='Test de DAG',
schedule_interval=timedelta(days=1),
)
t1 = BashOperator(
task_id='print_date',
bash_command='date',
dag=dag,
)
t1.doc_md = """\
#### Documentation
On peut décrire ici notre DAG
"""
t2 = BashOperator(
task_id='sleep',
depends_on_past=False,
bash_command='sleep 5',
retries=3,
dag=dag,
)
dag.doc_md = __doc__
t1 >> t2
Conclusion :
Airflow est trés pratique pour automatiser tous les processus possibles. Le large choix d'opérateurs permet de laisser libre cours à son imagination et de faciliter la gestion de son architecture de données. Il reste néanmoins lourd à déployer et configurer correctement même si le gain de temps une fois lancé en vaut le coup. Son interface grahique dans laquelle on a toutes les informations (logs, graphiques de temps, code...) est trés agrèable. Un bémol est le manque d'une plus grande communauté (même si c'est le plus connu pour faire ce type de fonctions) notamment sur StackOverflow, ce qui rend parfois la résolution d'erreurs compliquée.
Merci de votre lecture et n'hésitez pas à m'envoyer vos commentaires si vous avez eu une expérience avec Airflow ou si vous voulez en savoir plus !
Florian
Sources & pour aller plus loin :