
Je vous accompagne de l'audit à l'amélioration ou la création de votre architecture data.
À propos
Développeur en traitement de données sous toutes ses formes : de la visualisation à la création de processus, en passant par l'IA.
- Indépendant depuis 2018 pour grandes entreprises, cabinets de conseil, startups et PME.
- Développement d'architecture data : Création d'ETL, orchestration, déploiements sur le cloud, valorisation des données (visualisation, machine learning, automatisation).
- Impliqué et orienté performance : Exigence sur la qualité et les résultats pour mes clients.
- Basé à Montpellier avec des déplacements réguliers à Paris. Habitué à travailler en distanciel.
- Veille & partage : Passionné par les nouvelles technologies, je partage mes découvertes sur mon blog.
Offre
Audit Flash
Durée : 1/2 journée
- Préparation des entretiens
- Entretiens en visio avec retours et conseils en direct
- Synthèse des échanges dans un document
- Objectif : Débloquer des points précis et recommandations stratégiques et macro
Audit poussé
Durée : 3 jours
- Exploration approfondie de l'architecture data
- Entretiens avec les métiers, CTO, Head of Data et l'équipe (Data Engineers, Analystes, Data Scientists, Software Engineers...)
- Analyse de la base de code et de la documentation
- Retours documentés avec forces, faiblesses et recommandations
- Feuille de route
Accompagnement
Durée : 1 à 2 jours par semaine
- Accompagnement des équipes dans la mise en place d'architectures
- Développement de fonctionnalités précises
- Refactoring et nettoyage d'architectures
Renfort
Durée : Variable (semaines à mois)
- Mise en place et amélioration d'architectures
- Montée en compétence des équipes
- Mise en place de processus de développement
- Management
- Compensation de sous-effectifs ou départs
Compétences
Collecte et transformation de données
- Développement de chaînes de traitement de données ETL (Extract Transform Load) en Python.
- Mise en place d'outils tels que DBT (orchestration de requêtes SQL) et Airflow (ETL Python).
- Collecte de données auprès de services tiers via interface API (comme Google, Slack ou Teams) et sur des services de stockage (base de données, serveurs FTP, stockage de fichiers).
- Développement de programmes de Scraping pour extraire les données de site web
Création de bases de données
- Définition avec le client du schéma de données avec les attributs et indicateurs pertinents avec l'usage final
- Mise en production sur un service Cloud et sécurisation
- Développement des connecteurs permettant d'ajouter les données
- Développement de requêtes SQL
Types de base de données avec lesquelles j'ai l'habitude de travailler :
Datawarehouse(BigQuery), DataLake(Bucket S3, Google Cloud Storage ou FTP), PostgreSQL (relationnelle en SQL), MongoDB (orientée document), InfluxDB (Séries temporelles) et Neo4j (orienté graph)
Valorisation de données existantes
- Création de Tableau de Bord (Data Studio, Tableau, PowerBI)
- Développement d'algorithmes de prédiction (Machine Learning) en Python: Algorithmes de Clustering, Réseaux de neurones et regressions par exemple.
- Création d'automatisations via des outils de NoCode comme Zapier, Make ou N8N pour des cas d'usage bien définis.
Outils de Business Intelligence avec lesquels j'ai l'habitude de travailler :
Google Data Studio, Dash, Grafana, Tableau Software et PowerBI
Création de Backend Web / API
- Développement de serveurs API permettant d'ouvrir les données d'une base de données par exemple.
- Création d'authentifications via API comme OAuth 2.0, tokens JWT, services tiers comme Firebase ou API Key.
- Mise en production avec des reverse proxy comme NGINX, Apache ou Traefik pour gérer plusieurs services et HTTPS entre autres.
Langages Web avec lesquels j'ai l'habitude de travailler :
Flask en Python et Node.JS en Javascript.
Architecture Cloud
- Déploiement de services sur des services Cloud via Docker ou autre
- Configuration réseau des services
- Sécurisation: par exemple configuration de firewalls, whitelist IP, backup, mirroring, HTTPS etc
- Versioning via Git
- Mise en place de tests
Services Cloud avec lesquels j'ai l'habitude de travailler :
Microsoft Azure, Google Cloud Platform (GCP), OVH, Amazon Web Services (AWS) et Oracle
Compétences non techniques
- Définitions de modèles économiques autour des données et d'une stratégie d'utilisation des données.
- Formations aux outils permettant de manipuler des données et aux langages de programmation.
- Vulgarisation de sujets techniques
Références Client
Pilotage de la transformation organisationnelle et technique d'un pôle Data de 10 personnes.
Mise en place de DBT, formation des équipes et refonte du modèle de données pour passer sur un modèle en couches Médaillon (silver/gold/datamart/sémantique).
Structuration de l'équipe et conduite du changement
- Coordination d'équipe : Management transverse de 10 collaborateurs (6 Data Analysts, 4 Data Engineers) pour aligner les objectifs techniques et business.
- Animation de la vie d'équipe : Instauration de rituels agiles (Daily, Weekly) et organisation de sessions de partage de compétences pour favoriser la montée en gamme collective.
- Pilotage de l'activité : Déploiement de Jira pour la gestion du ticketing, apportant une visibilité accrue sur la vélocité et les priorités du pôle.
- Acculturation technique : Onboarding généralisé sur dbt, permettant d'unifier les méthodes de travail et de diffuser les bonnes pratiques SQL au sein de l'ensemble de l'équipe.
- Standardisation du code : Implémentation de Git (GitLab) couplée à un processus de review et de Merge Request, garantissant la qualité des livrables.
Refonte de l’architecture et migration technique
- Transition vers l'Architecture Médaillon : Conception d'une trajectoire technique pour implémenter une structure en couches (Bronze, Silver, Gold), assurant la mise à disposition d'une couche "Gold" certifiée.
- Migration des vues, "scheduled queries" et procédures stockées SQL Server qui alimentaient les dashboards Power BI et les modèles de Machine Learning.
- Mutualisation du Transform : Centralisation de la logique métier dans dbt, facilitant la maintenance et la réutilisation des modèles de données à travers l'organisation.
- Modernisation de l'orchestration : Définition d'une roadmap Data Engineering pour migrer les scripts Python/Cron isolés vers un Airflow centralisé, fiabilisant ainsi l'ensemble des extractions.

Analyse de données Marketing avec Collectif Bulldozer Mission d'audit de data marketing .Utilisation de Metabase et de SQL. Audit du tracking des Ads et du CRM Salesforce.
-
Mission menée avec le collectif de freelances marketing Bulldozer.
Nous étions 4 : un expert publicités en ligne, un spéciaisé en SEO, un en stratégie d'acquisition outbound et moi en data.
Notre but était d'auditer le service marketing B2B afin d'optimiser les taux de conversion et les coûts d'acquisition client.
Pour cela j'ai eu accès à leur Metabase connecté à leur datawarehouse ce qui m'a permis de faire une analyse poussée (en SQL) des taux de conversion par canal et tout au long du tunnel de vente ainsi que de mesurer les coûts d'acquisition.
Nous avons pu présenter une roadmap au comex.
Audit et amélioration des performances de traitement de données. Intégration à l'équipe data (6 personnes). Utilisation de SQL avec DBT et extractions avec Airflow et Airbyte. Datalake et Datawarehouse sur AWS avec Athena et S3.
-
Data Engineer Freelance.
- Audit de l'utilisation de DBT et Airflow et recommandations d'amélioration.
- Migration de requêtes SQL de données de campagnes publicitaires vers DBT (connecté à AWS Athena) avec intégration dans le modèle de données existant.
- Refactoring du modèle de données (Architecture Medaillon avec du Kimball) en SQL avec DBT. Refactoring de certains DAGs Airflow.
- Création d'une couche de datamarts sur Aurora Postgres pour ouvrir les données au backend avec de meilleures latences.
- Amélioration du pipeline de CI/CD de DBT sur Github.
Renfort technique pour la conception et l’amélioration des systèmes de gestion de campagnes publicitaires. Mission de développement Backend (Python Flask Serverless sur AWS et BDD PostgreSQL) et traitement de données (DBT, SQL et Airbyte).
-
Senior Backend Développeur / Data Engineer Freelance.
- Renfort technique pour la conception et l’amélioration des systèmes de gestion de campagnes publicitaires.
- Environnement serverless sur AWS en Python / SQL via Flask et PostgreSQL. Attention particulière à la qualité du code avec des tests unitaires et e2e et une chaîne de CI/CD robuste.
- Création de data pipelines en Python et via DBT. Mise en place de la CI/CD avec terraform et Github Actions pour tenir à jour certaines extractions utilisant Airbyte.
- Maintenance et amélioration du backend relatif au traitement des données de finance de l’entreprise.
- Mise en place d’outils pour piloter la marge et les indicateurs financiers.
Client basé à Londres et donc mission en Anglais. Développement d'ETL Python sur Airflow. Mise en production de DBT et de centaines de requêtes SQL de transformation de données. Gestion du datawarehouse (BigQuery) et lien avec les équipes métier. Développement de tableaux de bord sur Looker Studio.
-
Senior Data Engineer Freelance en 100% télétravail avec déplacements à Londres et Paris.
- Maintenance et Développement de DAG Airflow en Python pour extraire les données de CRM, backends, bases de données, et plusieurs autres systèmes.
- Migration de centaines de requêtes SQL vers DBT et configuration de l'environnement.
- Création d'un script de synchronization entre les données du datawarehouse et l'ERP (logiciel de comptabilité) Oracle Netsuite.
- Développement de requêtes SQL pour pouvoir ouvrir la donnée sur Looker Studio (ex Google Data Studio)
- Gestion du datawarehouse sur BigQuery et du datalake Google Cloud Storage
- Création de dashboards et exports automatisés pour le métier.
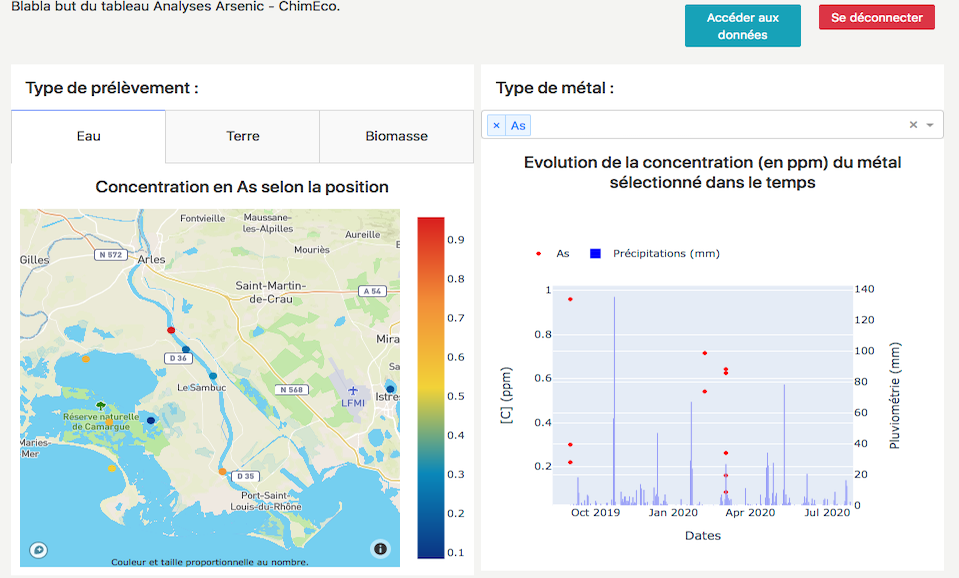
Création d'un tableau de bord pour interpréter les données d'analyse collectées
-
Projet de CNRS innovation
- Recueil du besoin et des indicateurs à mettre en avant auprès des équipes du labo impliquées
- Mise en forme de la donnée et connection à des sources de données externes (via API) pour enrichir.
- Création de la plateforme en Python avec la bibliothèque Dash
- Mise en service au sein du labo pour garantir un accès aux personnes impliquées
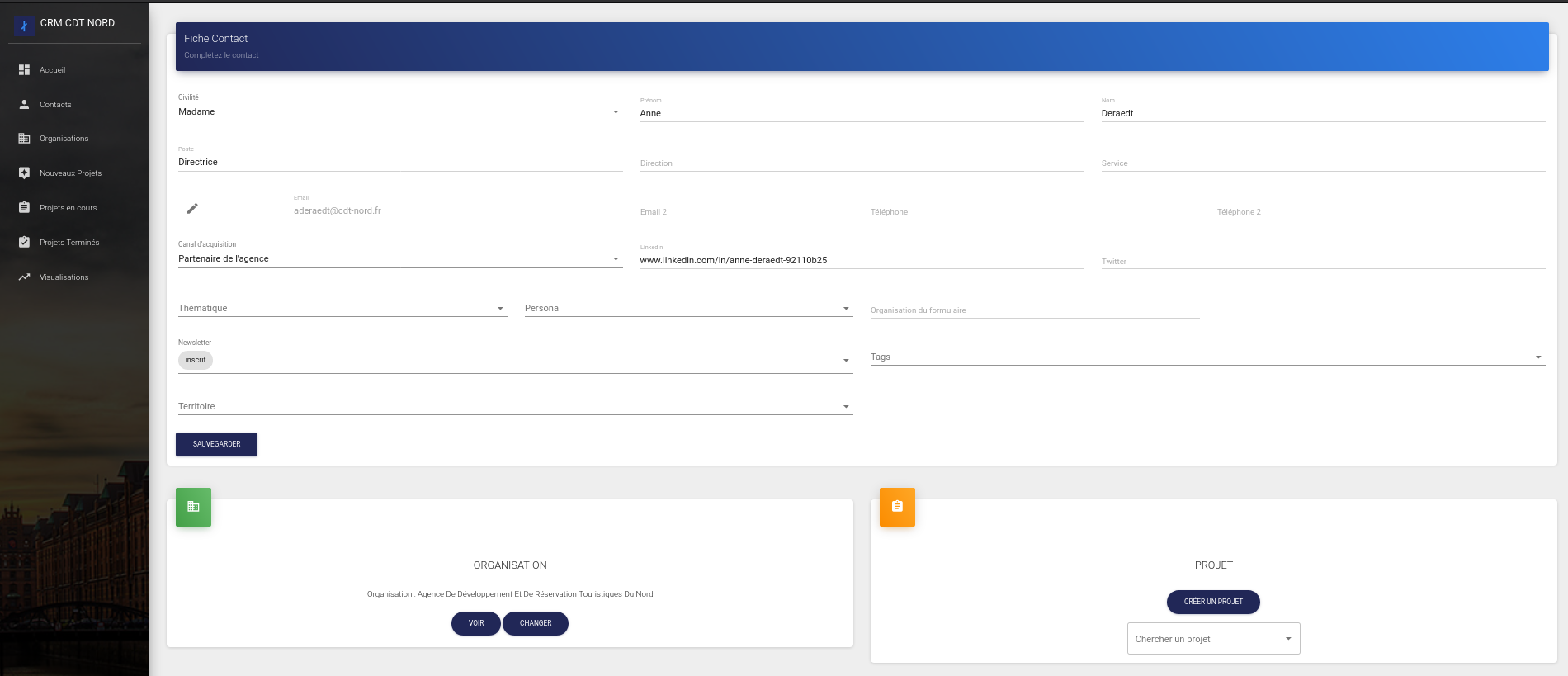
Accompagnement du comité départementale du tourisme sur la mise en ligne d'une plateforme Open Data. Création des extractions et transformations de données auprès des partenaires de l'agence. Développement d'un CRM sur mesure pour la gestion des projets.
- Recueil des besoins en terme de données dans l'agence.
- Création des fonctions d'extraction, transformation et load à partir des sources de données touristiques en Python.
- Développement d'un outil de gestion de projets (CRM) sur mesure en React.JS avec une API en backend qui permet d'interfacer une base de données MongoDB.
- Configuration de la plateforme Open Data à partir de l'outil OpenDataSoft et connexion au différentes sources de données.
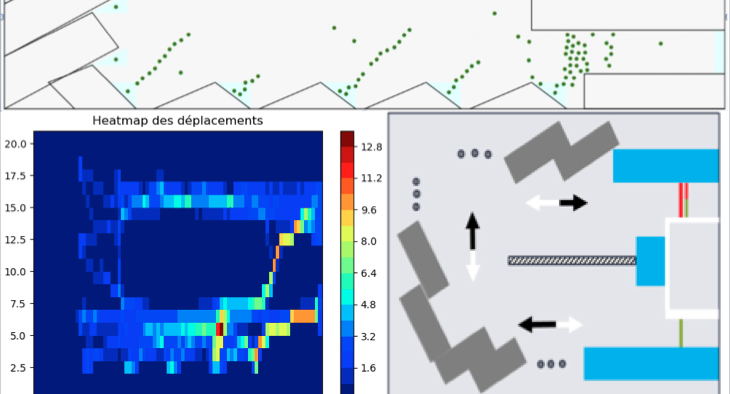
Développement d'un logiciel de simulation de flux piétons dans les décheteries afin d'optimiser le positionnement des bennes et la construction.
Durée : 6 mois à mi-temps
- Logiciel de simulation en Java
- Traitement des données statistiques en Python
Développement de tunnels d'extraction, transformation et stockage de données (ETL) depuis les API de Slack et Google vers des bases de données PostgreSQL sur Azure. Développement de modèles de prediction de l'attention d'utilisateurs à partir de leurs méta données de messages, emails, calendrier et visio-conférences.
-
Création de la première architecture technique et stratégie tech de la startup.
- Recueil du besoin pour élaborer un schéma de données puis création des bases de données
- Extraction via interfaces API des données Slack et Google afin de récupérer l'ensemble des méta-données de messages, mails, calendriers et visios. Création des tunnels de transformation de données en Python. Configuration de l'OAuth2.
- Mise en production de l'architecture sur le Cloud Azure et étude comparative des offres cloud. Mise en production sur serveurs d'outils de visualisation (Redash), d'automation (N8N) et de gestion de données (NocoDB). Configurations sur Docker.
- Sécurisation de l'architecture : mise en place de mirroring et backups automatiques sur les BDD, chiffrement des bases, whiteliste IP, configuration de firewalls.
- Développement d'algorithmes permettant de mesurer l'attention des utilisateurs à partir des méta-données.
Mise en place d'une routine de collecte et transformation de gros volumes de fichiers XML et ajout de centaines de millions de lignes en base de données PostgreSQL pour ensuite une utilisation avec Tableau software.
- Développement des scripts de collecte et transformation en Python et Bash (des Go de fichiers XML à mettre en forme)
- Configuration en environnement de développement et en production de la base de données PostgreSQL (des centaines de million de lignes à stocker)
- Suivi quotidien avec le client et création de la documentation au fur et à mesure
- Mise en production sur serveurs OVH
- Visualisation des données avec Tableau software
Conseil en Data Science en Freelance pour le cabinet Onepoint. Développement de prototypes de Machine Learning et recherches de cas d'usage de l'Intelligence Artificielle pour des clients.
- Création de documents client de benchmark, veille et recherche de cas d'usage
- Développements de prototypes en Python avec souvent une composante Web pour arriver à un produit finit.
- Prototypes avec de la donnée textuelle (NLP), image (Computer Vision) et algorithmes de recommandation.
- Développement de serveurs sur le cloud Microsoft Azure et Raspberry Pi
Conseil en traitement de données & IA en Freelance pour le cabinet de conseil en management Deloitte. Mise en place d'une infrastructure de collecte et d'analyse de gros volumes de données pour analyser un sous marché automobile pour leur client.
- Mise en place d'une architecture de collecte de donnée sur le cloud Amazon Web Service
- Création de scripts de scraping (récupération de données du web de façon automatique) en Python avec des méthodes de contournement et des proxies pour changer les IP.
- Analyse des gros volumes de données récupérés
- Rédaction d'un rapport sur la concurrence de notre client à partir des statistiques obtenues
Avis Clients
Head of Data à Mobsuccess Group
Chargé d'une mission courte, Florian a pris en main extrêmement vite les données métiers et notre Stack DBT, permettant de faire une migration rapide de requêtes SQL pas encore intégrée à nos modèles de données. De très bon conseil technique avec une valeur ajoutée métier bien présente.
Gérante à Budaviz
En plus d'un relationnel très agréable, Florian est consciencieux, rigoureux, à l'écoute tout en étant force de proposition. Florian a très vite compris mes besoins, à savoir la mise en place d'une base de données regroupant certaines données publiques que je souhaitais exploiter sur Tableau software. Il a réalisé plusieurs scripts permettant d'automatiser la mise à jour quotidienne de la base de données et fait le nécessaire pour installer ensuite celle-ci sur un serveur. Il m'a épaulée dans le choix d'une formule d'hébergement pour le serveur. Le travail rendu est très propre et bien documenté. Un vrai talent que je recommande totalement.
CTO à Onefinestay (Groupe Accor)
Florian has been working with us for 2 years. Initially, it was for a 6 months contract, consisting in migrating our data pipelines to work with the new systems we were implementing at time. Florian did very well, understood the business concepts quickly, our tech environment as well, meaning that the job was achieved in time, although it was not very easy with the amount of legacy transformation queries we had at the time. Since everything was going well, and that we had growing internal needs, I decided to continue working with Florian. He continued to clean up our legacy systems, and he migrated our whole ELT processes into DBT. He prepared training slides, and trained the teams internally. The job was achieved in less than 2 months. This greatly improved our ways of working, thus the internal teams satisfaction. Florian also worked on pushing our financial data coming from our backoffices to NetSuite. This was a very complex project, with multiple NetSuite customization needed. Florian never abandoned, even though it was really difficult to get all the required information sometimes. Florian worked on many other structural and strategic projects during these 2 years, and he never let me down. The only reason we had to stop working together is because we wanted to internalize the position, but Florian wanted to remain as a contractor, which I can fully understand. Florian is a true gem, he can work on very complex projects, and go to the bottom of them, without any doubts. He is also a very nice person, which is always a nice addition :) We will miss him, for sure.
Principe des Réseaux de données
Certification Institut Mines Télécom
Web sémantique et Web de données
Certification INRIA

Expériences et Formation

Réalisation de prestations en informatique pour tout type d'entreprises
Dévelopement de projets de traitement et valorisation des donneés de mes clients.
Voir les compétences
Voir les missions réalisées

Startup spécialisée dans le déplacement des personnes à mobilité réduite.
- Mise en place de la stratégie avec mes associés, qui développent la partie commerciale et recueillent les besoins utilisateur.
- Création de la société sur le plan juridique, gestion de la comptabilité et l'administratif.
Développement du système d'information et des services :
- Développement de l'architecture de collecte, transformation et stockage des données cartographiques avec ouverture via des APIs REST et GraphQL. Déploiement sur 2 services de Cloud. (Outils d'architecture et de Back-end)
- Programation de 3 sites web avec React.JS et JQuery pour des clients et des outils de gestion de données interne. (Technos de Front-end)

DELOITTE Conseil
Service Analytics & Information Management (AIM) qui développe et met en production des projets d’Intelligence Artificielle (IA).
- Développement d'algorithmes de machine learning sur du texte (Natural Language Processing) pour de la classification automatique de mails
- Programation d'un prototype de traitement automatique de factures avec des algorithmes d'extraction de texte d'images (OCR) et avec le texte obtenu d'algorithmes de reconnaissance d'entités nommées (Named Entity Recognition)
- Mission client sur de la collecte et analyse de gros volumes de données pour en faire l'analyse dans le secteur automobile.

Startup spécialisée dans la capture d'images hyper spectrales à partir de drones
Elaboration d’une stratégie de Deep learning pour une application de reconnaissance de formes à partir d’un capteur hyperspectral miniaturisé sur smartphone.
- Utilisation de Python et de la bibliothèque Tensorflow
- Virtualisation de l'environnement de traitement de la donnée avec Docker
- Rédaction d'un rapport des cas d'usage possibles des Réseaux de Neurones pour la startup
Grenoble, France
- Diplôme Parcours Grande Ecole :
- Comptabilité et gouvernance d'entreprise
- Cours de négociation et vente
- TOEIC : 915/990
- Mémoire de fin d'études : "Les impacts métiers de l'utilisation de la donnée et ses enjeux éthiques".
Brest, France
- Diplôme d'ingénieur en Data Science :
- Machine Learning
- Business Intelligence
- Big Data
- TOEFL : 620/677
Shanghai Jiao Tong University
(SJTU)Shanghai, Chine
- Échange universitaire de 6 mois
- Data Science / Big Data
Classes préparatoires
Math-Physique (PSI*)Lycée Joffre Montpellier, France
