DBT : Portons la transformation de données à un niveau supérieur
- Publié:
DBT (pour Data Build Tool) est un outil open source permettant de transformer les données d'un datawarehouse (Google BigQuery, Amazon Redshift, Snowflake, PostgreSQL... doc) en orchestrant des requêtes SQL.
L'outil se base sur les tables de ces bases de données (BDD) pour créer de nouvelles tables, vues ou incrémentations.
En fait DBT est une couche au dessus de ces BDD, il n'éxécute rien, il s'occupe de compiler les requêtes SQL et les envoyer au bon moment aux BDD pour être éxécutées.
1. C'est quoi DBT ?
C'est un package python open source (7.5K ⭐) nommé DBT Core (Github) sur lequel la société DBT Lab a créé un service sous abonnement DBT Cloud qui est un IDE online permettant d'utiliser DBT core. Ce logiciel en ligne permet d'écrirer du code SQL sans avoir à s'occuper de la configuration des serveurs et de maintenir une architecture.
DBT Core
DBT peut être utilisé directement en ligne de commande en local après installation du package.Je ne vais pas entrer dans le détail de la configuration de l'arborescence et des connexions aux bases de données, vous trouverez tout ici : https://docs.getdbt.com/docs/core/about-the-cli
Le principe est assez simple, les fichiers contenant les requêtes SQL (appelés "models" dans DBT) sont stockées dans un dossier models. On peut éxécuter ensuite chaque table avec la commande
dbt run --select nom_table .
Le nom de la table créée est le nom du fichier avec l'extension .sql.
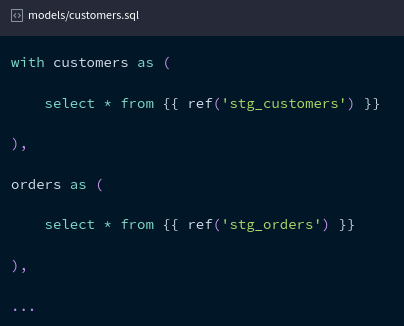
{{ ref('nom_table') }} si c'est un autre model ou {{ source('nom_dataset', 'nom_table') }} si c'est une table source. Ce templating en langage Jinja permet de remplacer dynamiquement les noms des tables lors de la configuration et permet surtout à DBT de reconstruire le graph de dépendance des tables.

Lorsqu'on travaille sur une table il est du coup possible d'éxécuter :
- seulement les tables amont :
dbt run --select +table - celles en aval de la table de travail :
dbt run --select table+ - toutes les dépendances avant et après :
dbt run --select +table+
DBT Cloud :
2. Les fonctionnalités qui le rendent indispensable
- l'orchestration de requêtes
C'est la fonctionnalité que je trouve la plus intéressante, ne plus se soucier de l'ordre dans lequel éxécuter les requêtes pour que la donnée soit à jour. - test / freshness
DBT permet de créer des fichiers yml dans chaque dossier et de configurer à l'intérieur de ceux ci les dépendances entre models avec les clés de jointure ainsi que des tests d'unicité, non null, range de valeurs... Il est aussi possible de créer des tests métiers plus compliqués sous forme de requête SQL (stockées dans le dossier /tests). Si la requête renvoie des lignes c'est que le test échoue. Ces tests peuvent être éxécutés pendant le développement et en production pour s'assurer de la cohérence de la donnée.
La freshness permet de définir un interval d'actualisation d'une table pour être sûr que les données sont à jour.
Autant les tests que la freshness peuvent être configurés pour générer des alertes mails/slack. - docs descriptions metadata
Dans les fichiers .yml il est possible de définir la description des tables et des colonnes en même temps que les tests vus précédement. De plus il existe le concept d'exposure qui permet de lister les dashboards ou applications qui utilisent des tables sources ou des models de DBT. Ceci est très utile car ça permet de voir très facilement le flux de données de la table source extraite jusqu'à l'application finale. En éxécutant la commandedbt docs generateDBT compile toutes les méta données et les fichiers .yml pour créer un espace de documentation sur lequel on peut voir les caractéristiques des tables, liens entre elles et le code. - Jinja templating
DBT se base sur le langage de tempalting jinja pour permettre de créer dynamiquement des requêtes SQL. Il est ainsi possible d'ajouter des conditions, itérations etc pour créer du SQL.
3. Pour aller plus loin :
Il est possible de créer des macros en Jinja qui permettent de changer le comportement de DBT.
Par exemple si on veut un comportement spécifique telle que l'application d'un filtre juste en environnement de développement.
Il est possible d'importer des macros grâce aux packages DBT. Les packages sont configurés dans le fichier packages.yml . https://docs.getdbt.com/docs/build/packages
et installés avec la commande dbt deps .
Il existe par exemple le package dbt-utils qui permet d'ajouter plus de tests et de fonctions de compilation entre autre.
packages:
- git: "https://github.com/dbt-labs/dbt-utils.git"
revision: 0.9.2 # tag or branch name
Conclusion :
DBT est l'outil parfait lorsqu'on commence à avoir plusieurs requêtes SQL de transformation et donc un graph de dépendances. En effet il nous permet de développer plus en vite en ayant une vision globale du flux de données tout en donnant des outils permettant de vérifier la data quality et assurer la documentation.
Merci de votre lecture et n'hésitez pas à m'envoyer vos commentaires si vous avez eu une expérience avec Airflow ou si vous voulez en savoir plus !
Florian
Sources & pour aller plus loin :